Vocalizer API
With the Vocalizer API, the Vocalizer service is fully implemented by libraries (DLLs or shared objects) linked in by the user’s application.
Vocalizer supports the following APIs:
- Nuance Vocalizer native C API
- Microsoft SAPI 5 API (Windows only)
The Vocalizer clients sends API calls to Vocalizer. You integrate the Vocalizer client with the user application.
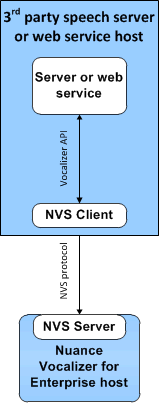
On Windows, the Vocalizer API library is named lhstts.dll (with a corresponding import library lhstts.lib). On Unix, the library is named lhstts.so. The library resides in the install_path\common\speech\components subdirectory of the Vocalizer installation directory. The Vocalizer installer does not automatically add the library to the library load path. This is the only library the application is required to link in or explicitly load in order to use the TTS functionality.
Use of Vocalizer in telephony environments
There are three components to any telephony application using speech technology:
- The main application
- The telephony device
- The speech engines: text-to-speech and/or speech recognition
The main application serves as the brain of the entire system, and is responsible for the overall setup and control of the speech engines and telephony devices. The main application is the master of the system; the telephony device and the speech engines are slaves to the main application.
The telephony device is the point at which voice input or output occurs in the telephony application. In traditional telephony applications, the point of entry is the telephony voice board.
Telephony applications serve many customers at the same time. The concept of a voice port is often used. Each voice port serves one customer at a time. One port is usually associated with one telephone line.
Typically, a telephony application directs all TTS requests for one telephone call or dialog session to the same TTS engine instance. The term call refers to a telephone call by a customer or any form of dialog session.
The application can create and destroy the engine instance for each call, but it is usually more efficient to keep the instance alive across calls; this means one TTS engine instance is assigned to one voice port for a lifetime that is usually much longer than one call.
To reuse a TTS engine instance, the application must restore the engine instance to a well-known state before reusing it for another call. This is needed when the settings of an instance are changed in the course of one call (for example, adjusting the volume, switching the voice or language, loading user dictionaries).
For the API, Vocalizer uses a synchronous (blocking) function for synthesis, so the application must use multiple threads to allow concurrent handling of multiple voice ports. Vocalizer usually creates one thread for each voice port. The Destination callback streams the audio back to the telephone application. The application uses the first argument of the Destination callback, the application data pointer, to direct the audio to the appropriate voice port.
Realtime responsiveness and audio streaming
To support realtime audio streaming, Vocalizer attempts to return audio chunks at a rate that is faster or equal to the play-back rate. Vocalizer minimizes the latency for each TTS request by sending audio back as soon as the buffer provided by the application fills completely.
The application can play chunks of speech as soon as they are received from Vocalizer. For the native API, the Destination callback must return as soon as possible to allow the instance to process the rest of the speech unit, sentence, or text, and fill a next buffer with audio before the audio of the previous buffer finishes playing. The applications decides the size of the output chunk: for efficiency it must not be too small, but to minimize the latency it must not be too big. A good compromise is a buffer big enough for half a second of audio rounded up to the nearest 1K boundary. (For example, 4096 bytes for 8 kHz sampling rate audio in µ-law or A-law format, or 8192 bytes for 8 kHz sampling rate audio in linear 16-bit PCM format.)
The above explains that the latency for the first audio chunk of a sentence is usually longer than for the following chunks, which is convenient since the effect of an underrun at the start of a sentence is less critical: it results in a longer pause between two sentences.
The latency also depends on the type of input text. You must provision Vocalizer with an adequate safety margin for the possible variance in the latency. For instance, if most TTS requests consist of a text with normal sentences, but a few may have extremely long sentences (for example, poorly punctuated e-mails), then make allowances for situations where the TTS engine instance deals with long sections of text with no punctuation. Such an occurrence may result in an extended inter-sentence latency, normally audible as a longer pause between two sentences. To reduce the risk for extended inter-sentence latencies, the engine will split up very long sentences at an appropriate location (such as a phrase boundary). It is very rare to have a natural sentence that long. (The length depends on the language and the sentence’s content, but it’s usually around 750 characters.)
Note that when serving multiple voice ports, instances are not influenced by the badly punctuated input of another instance.
If an audio chunk is delivered after the previous chunk has finished playing, users will hear a gap in the speech output. Such an intra-sentence gap can have a stronger audible effect: for example, it can occur within a word, and often sounds like a click. Such an “underrun” only starts to appear when operating Vocalizer at very high density levels (at or above the computer’s processing capacity), or when other processes on the system are consuming a lot of CPU. The application can mask the effects by maintaining a queue of audio chunks which allows audio output to accumulate faster than real time to compensate for the rare occasion of a non-realtime response. Most audio output devices support the queuing or buffering of audio chunks before they are effectively played out.
When using the native API, it’s safer for the Destination callback to return a buffer for the next chunk as soon as possible instead of waiting until the playback of the previous chunk has finished. When the instance runs faster than real time and the size of the queue grows too much, the application might insert some waiting (a fixed maximum on the number of buffers would then result in an overrun). Vocalizer’s throttling mechanism limits the audio chunk delivery rate to two times real time rate, thus reducing the risk for overruns. (By default, the first 5 seconds of generated audio are not throttled.)
Using Vocalizer from within multiple processes
Vocalizer supports multi-threaded programs where many simultaneous TTS instances are active at once within a single process, and it also supports multi-process environments. When multiple processes access Vocalizer at the same time on the same machine, you must configure Vocalizer’s behavior carefully. Otherwise the Internet fetch cache may grow larger than expected, or the log files can collide and get corrupted.
For the Internet fetch cache, you can share one cache directory across multiple processes. However, you must calculate the allocations for all other Internet fetch cache parameters on a per-process basis and adjust the cache_size parameter or server disk space appropriately. For example, if 10 processes use Vocalizer on the same computer at the same time with the same cache_directory and cache_total_size set to 200 MB, then the cache_directory could get as large as 2000 MB (200 MB * 10 processes).
The Vocalizer log files by default are disabled, so they will not collide in a multi-process environment. If you enable logs, and use Vocalizer in a multi-process environment, you must avoid log filename collisions using one of the following techniques:
- Instead of enabling logging, rely on Vocalizer’s logging to the operating system’s log or application-provided logging callbacks. For details, see Error and diagnostic logging.
- Run each process under a separate user account. By default, all log filenames include the username for the running process, making them unique.
- Set the Vocalizer temporary files directory TMPDIR as an environment variable, with a unique value for each process. By default, all the log files are created under TMPDIR, making them unique. This directory must exist before the process starts using Vocalizer.
- Modify the log file paths within the Vocalizer configuration file to include ${PID}, a variable for the current OS process ID, to make the paths unique for each process. Alternatively, you can use an application-defined environment variable that has a unique value for each process. For example, use an application-specific environment variable called SERVER_ID that stores a unique server instance number, and then use ${SERVER_ID} within the Vocalizer configuration file.
- Create separate user XML configuration files for each process, and manually configure unique log file paths for each. This can be done by copying the Vocalizer configuration file (install_path\config\tts_config.xml) to a new file, then removing all the parameters except the ones that need to be overridden; either just TMPDIR, or all of the log file paths. For native C API integrations, specify a different user XML file for each process when calling TtsSystemInit.
